
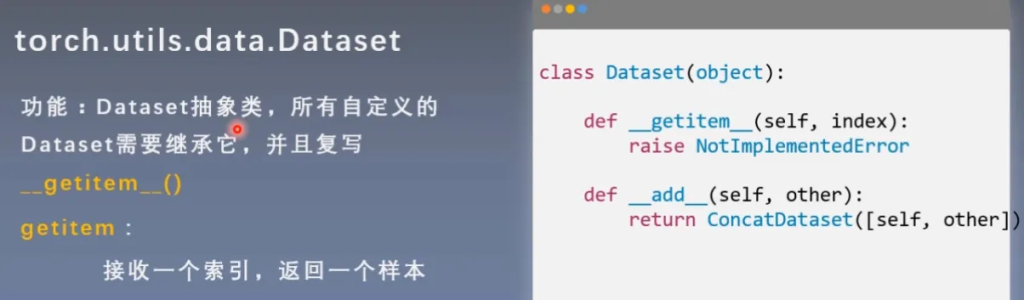
DataLoader与DataSet
人民币二分类问题
假如我们要对100元和1元人民币进行二分类,那么我们需要输入图片作为数据,这与之前输入的数据形式完全不同,我们应该如何实现呢?
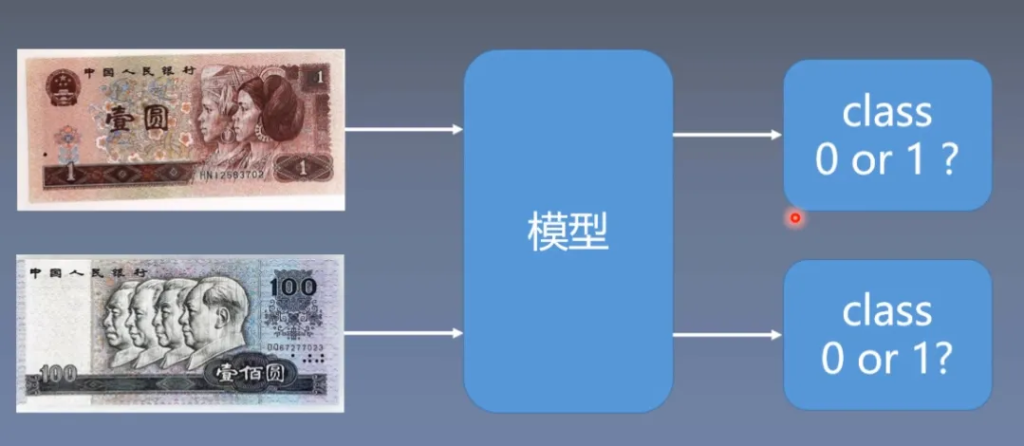
在Pytorch中,为我们提供了DataLoader来进行图片数据的读取
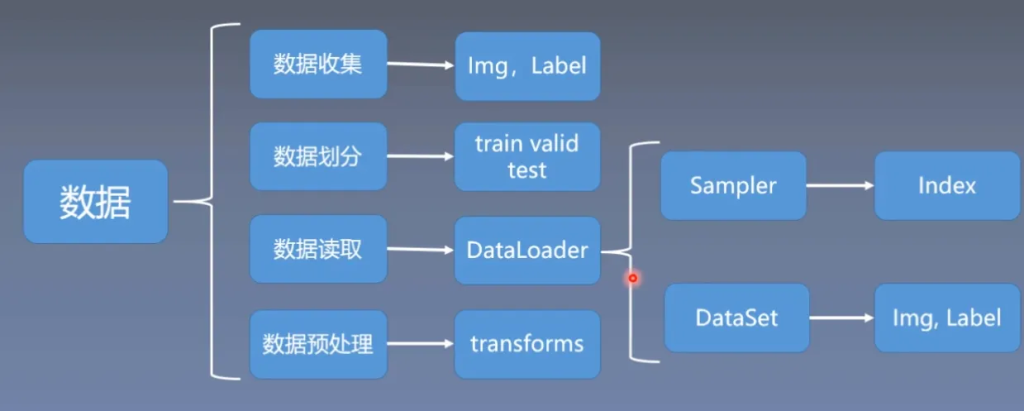
Sampler:给数据生成索引
DataSet:根据索引来进行读取
接下来详细介绍DataLoader和DataSet
DataLoader
DataLoader的功能就是构建可迭代的数据装载器,其中有很多的参数可以调整,这里介绍5个常用的参数
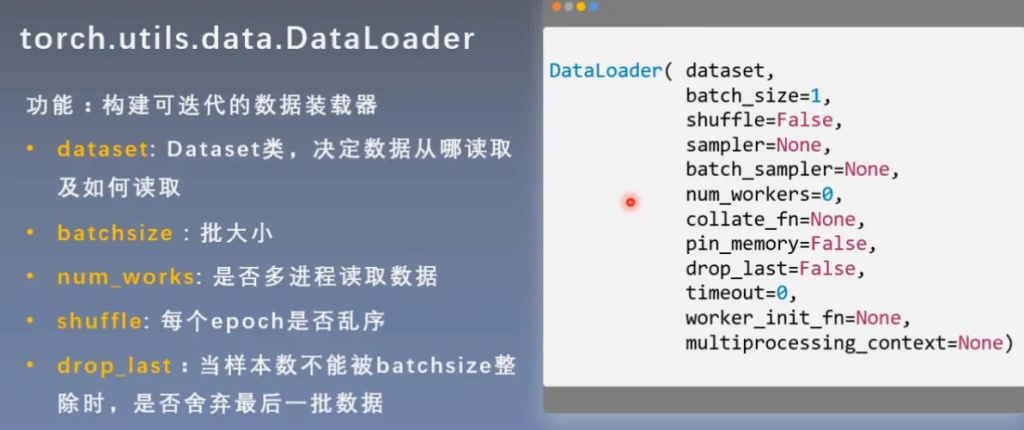
详细解释一下几个名词:
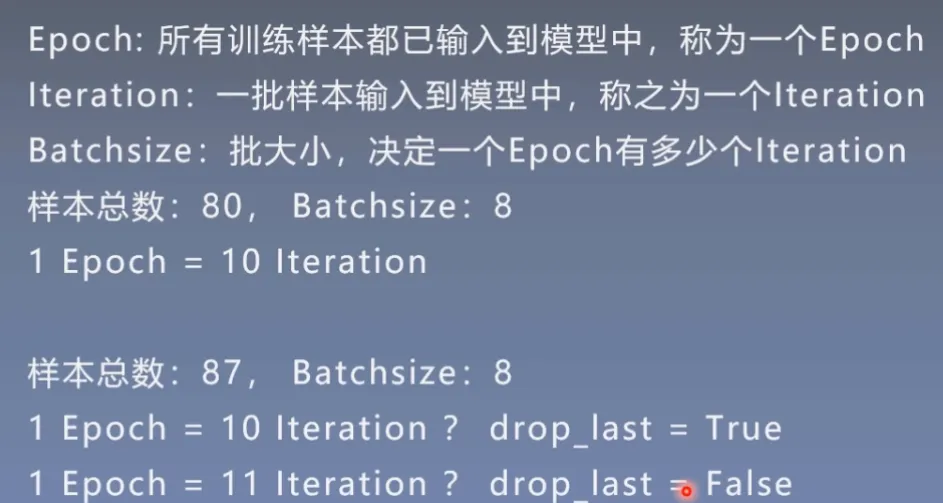
- Epoch:所有训练样本都已输入到模型中,称为一个Epoch
- Iteration:一批样本输入到模型中,称之为一个Iteration
- Batchsize:批大小,决定一个Epoch有多少个Iteration
举例说明:
如果样本总数为80,Batchsize为8,那么1 Epoch = 10 Iteration
那假如样本总数和Batchsize不能整除怎么处理呢?
这就与drop_last参数有关,是否舍弃最后一批数据
DataSet
人民币二分类项目
我们回到上面的问题中,通过项目代码来学习DataLoader和DataSet的运行逻辑,以及数据读取的三个问题。
划分训练集、验证集和测试集
首先我们打开split_dataset.py,这块代码的作用就是帮我们将数据人民币图片进行数据划分。
# -*- coding: utf-8 -*-
"""
# @file name : 1_split_dataset.py
# @author : tingsongyu
# @date : 2019-09-07 10:08:00
# @brief : 将数据集划分为训练集,验证集,测试集
"""
import os
import random
import shutil
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
if __name__ == '__main__':
random.seed(1)
dataset_dir = os.path.join("..", "..", "data", "RMB_data")
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs:
imgs = os.listdir(os.path.join(root, sub_dir))
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))
random.shuffle(imgs)
img_count = len(imgs)
train_point = int(img_count * train_pct)
valid_point = int(img_count * (train_pct + valid_pct))
for i in range(img_count):
if i < train_point:
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point:
out_dir = os.path.join(valid_dir, sub_dir)
else:
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir)
target_path = os.path.join(out_dir, imgs[i])
src_path = os.path.join(dataset_dir, sub_dir, imgs[i])
shutil.copy(src_path, target_path)
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
运行后,我们可以得到划分好的数据文件

模型训练
模型训练主要包含了五个部分:数据、模型、损失函数、优化器和训练。
# -*- coding: utf-8 -*-
"""
# @file name : train_lenet.py
# @author : tingsongyu
# @date : 2019-09-07 10:08:00
# @brief : 人民币分类模型训练
"""
import sys
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), "../../")))
import os
import random
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from model.lenet import LeNet
from tools.my_dataset import RMBDataset
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
set_seed() # 设置随机种子
rmb_label = {"1": 0, "100": 1}
# 参数设置
MAX_EPOCH = 10
BATCH_SIZE = 16
LR = 0.01
log_interval = 10
val_interval = 1
# ============================ step 1/5 数据 ============================
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
net.initialize_weights()
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss() # 选择损失函数
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
# ============================ step 5/5 训练 ============================
train_curve = list()
valid_curve = list()
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
outputs = net(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum().numpy()
# 打印训练信息
loss_mean += loss.item()
train_curve.append(loss.item())
if (i+1) % log_interval == 0:
loss_mean = loss_mean / log_interval
print("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))
loss_mean = 0.
scheduler.step() # 更新学习率
# validate the model
if (epoch+1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
outputs = net(inputs)
loss = criterion(outputs, labels)
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum().numpy()
loss_val += loss.item()
loss_val_epoch = loss_val / len(valid_loader)
valid_curve.append(loss_val_epoch)
# valid_curve.append(loss.item()) # 20191022改,记录整个epoch样本的loss,注意要取平均
print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(
epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_epoch, correct_val / total_val))
train_x = range(len(train_curve))
train_y = train_curve
train_iters = len(train_loader)
valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterations
valid_y = valid_curve
plt.plot(train_x, train_y, label='Train')
plt.plot(valid_x, valid_y, label='Valid')
plt.legend(loc='upper right')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.show()
# ============================ inference ============================
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
test_dir = os.path.join(BASE_DIR, "test_data")
test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
rmb = 1 if predicted.numpy()[0] == 0 else 100
print("模型获得{}元".format(rmb))可以先运行下,看看效果:
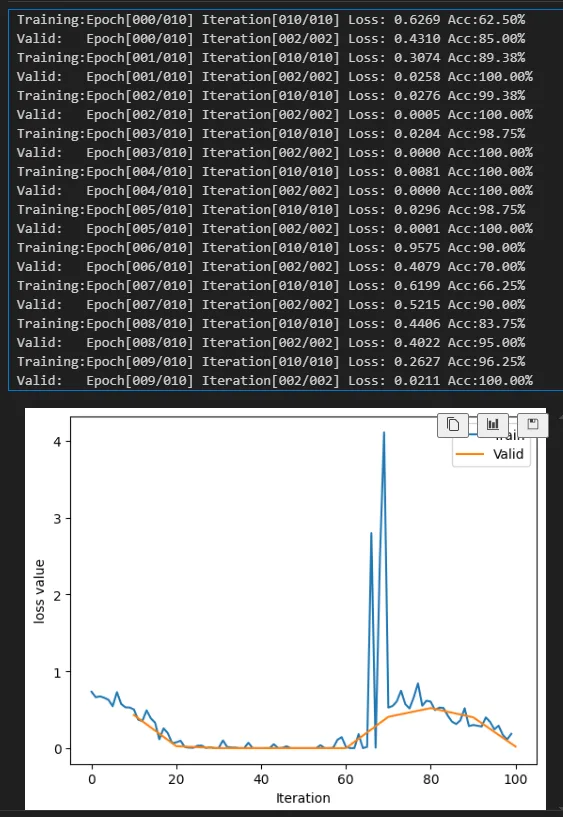
经过十轮的训练,最后画出了一个loss的图
接下来详细解释数据部分
数据部分
首先是定义数据的路径,将训练集和验证集的路径定义好
split_dir = os.path.join("..", "..", "data", "rmb_split")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")下一步对数据进行预处理,对数据进行一些变换,将其转换为张量
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])接下来就是重点,构建DataSet和DataLoader实例
构建DataSet实例主要有两个重要参数:数据路径(从哪里读取数据),数据预处理
# 构建MyDataset实例
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)上文介绍到,DataSet这个类,是需要我们自定义去写的,这里详细解释一下这个类是如何写的:
a. init,初始化这里就不多解释了
def __init__(self, data_dir, transform=None):
"""
rmb面额分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transformb. getitem,这个是类中的核心,主要是根据index索引来获取图片和标签
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, labelc. length,返回数据的长度
def __len__(self):
return len(self.data_info)d. get_img_info,自定写的方法,根据路径来获取数据的信息
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info回到原来的代码中,接下来构建DataLoader实例,传入DataSet实例,设置batchsize,shuffle表示是否乱序
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)数据读取
我们从模型训练部分,通过断点调试,详细看一下是如何进行数据读取的
for i, data in enumerate(train_loader):先跳转到dataloader.py,选择单进程读取还是多进程读取

以单进程为例,随后跳转到单进程类中这个函数,它会获取index和data
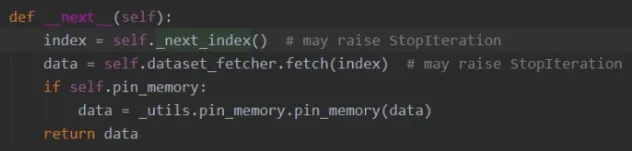
进入next_index这个函数中,能看sampler采样器

我们再进入sampler.py的sampler_iter中,这个函数就是告诉我们每个batch获取那些数据
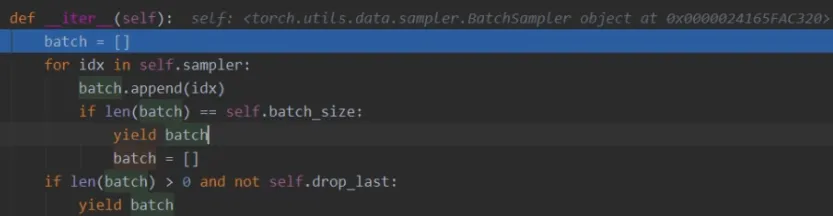
获取index后,我们回到这里,接下来看看data的获取
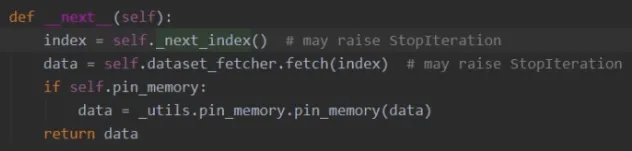
进入到fetch.py中,这里调用了dataset类,传入index,根据我们自定义的getitem函数来返回data
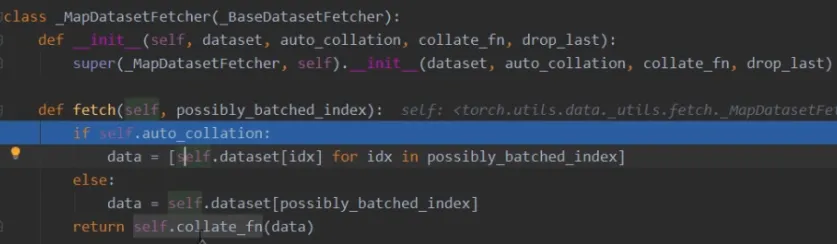
最后调用了collate_fn,这是个数据整理器,将数据整理为list的形式,返回。
总结
详细看了代码以后,我们整理一下整个数据读取的过程

用流程图来表示:
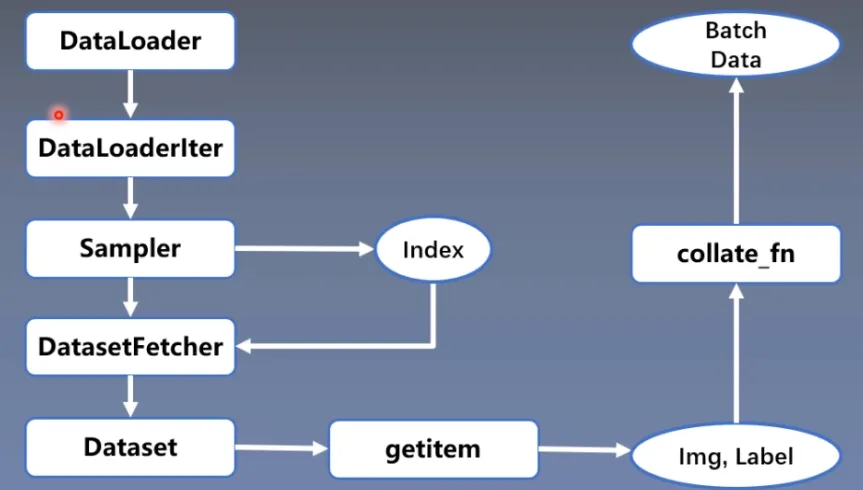
Transforms 图像预处理
Transforms
在之前安装包的时候,我们安装了torchvision包,也就是计算视觉工具包,它包含了一系列的工具

这里主要介绍transforms

我们可以看上一节RMB分类问题中的预处理部分:
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
valid_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])transforms.Compose:是对一系列变换的组合
transforms.Resize:对图像进行缩放
transforms.RandomCrop:随机裁剪
transforms.ToTensor:转成张量
transforms.Normalize:标准化
在上一节中详细说明了数据读取代码细节,这里也与上面一样,详细解释一下transforms的细节
从自定义的dataset类getitem函数开始,调用了transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label随后跳转到transforms.py,call函数,依次有序的进行transforms.Compose中预设的操作
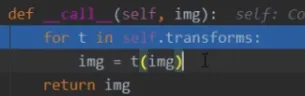
随后我们可以把transform加入到流程图中
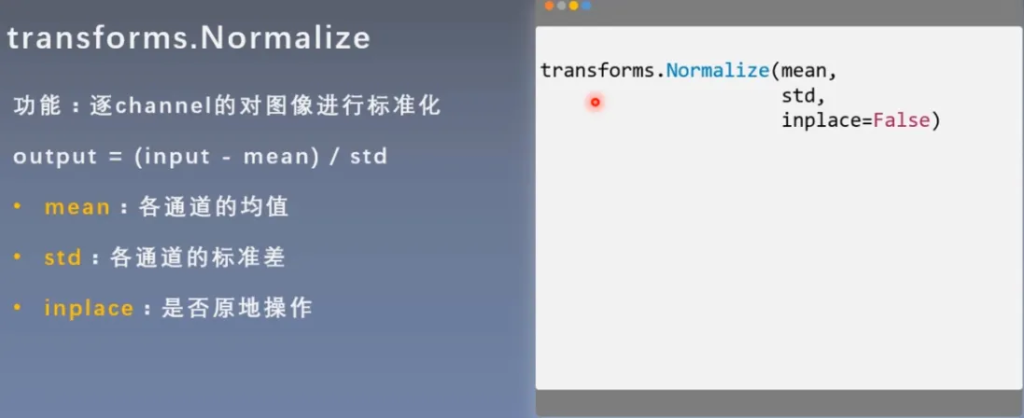
transforms.Normalize
将均值变为0,标准差变为1
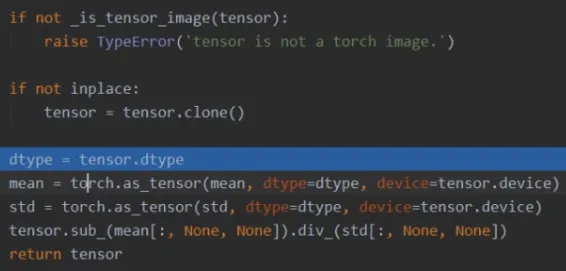
normalize的详细实现:
先判断是否为张量,下一步是否原地操作,否则克隆一份。
将均值和标准差转换为张量的形式,根据公式进行计算。
返回张量。
Transforms 图像增强(一)
数据增强
数据增强又称为数据增广,数据扩增,它是对训练集进行变换,使训练集更丰富,从而让模型更具泛化能力。
以这张图为例,通过一系列方式将图片变为更多张图片,供模型训练,让模型具有更强的泛化能力

裁剪 Crop
1. transforms.CenterCrop
功能:从图像中心裁剪图片
- size:所需裁剪图片尺寸

2. transforms.RandomCrop
功能:从图片中随机裁剪出尺寸为size的图片
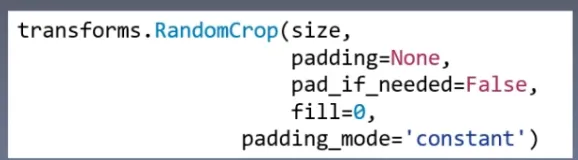
- size:所需裁剪图片尺寸
- padding:设置填充大小
- 当为a时,上下左右均填充a个像素
- 当为(a,b)时,上下填充b个像素,左右填充a个像素
- 当为(a,b,c,d)时,左、上、右、下分别填充a,b,c,d
- pad_if_need:若图像小于设定size,则填充
- padding_mode:填充模式,有4种模式
- constant:像素值由fill设定
- edge:像素值由图像边缘像素决定
- reflect:镜像填充,最后一个像素不镜像,eg:[1,2,3,4]→[3,2,1,2,3,4,3,2]
- symmetric:镜像填充,最后一个像素镜像,eg:[1,2,3,4]→[2,1,1,2,3,4,4,3]
- fill:constant时,设置填充的像素值
3. transforms.RandomResizedCrop
功能:随机大小、长宽比裁剪图片

- size:所需裁剪图片尺寸
- scale:随机裁剪面积比例,默认(0.08,1)
- ratio:随机长宽比,默认(3/4,4/3)
- interpolation:插值方法
4. transforms.FiveCrop
功能:在图像的上下左右以及中心裁剪出尺寸为size的5张图片

- size:所需裁剪图片尺寸
5. transforms.TenCrop
功能:TenCrop对这5张图片进行水平或者垂直镜像获得10张图片

- size:所需裁剪图片尺寸
- vertical_flip:是否垂直翻转
翻转 Flip 旋转 Rotation
1. RandomHorizontalFlip
2. RandomVerticalFlip
功能:依概率水平(左右)或垂直(上下)翻转图片

- p:翻转概率
3. RandomRotation
功能:随机旋转图片

- degrees:旋转角度
- 当为a时,在(-a,a)之间选择旋转角度
- 当为(a,b)时,在(a,b)之间选择旋转角度
- resample:重采样方法
- expand:是否扩大图片,以保持原图信息
- center:旋转点设置,默认中心旋转
Transforms 图像增强(二)
图像变换
1. Pad
功能:对图片边缘进行填充

- padding:设置填充大小
- 当为a时,上下左右均填充a个像素
- 当为(a,b)时,上下填充b个像素,左右填充a个像素
- 当为(a,b,c,d)时,左、上、右、下分别填充a,b,c,d
- padding_mode:填充模式,有4种模式,constant、edge、reflect和symmetric
- fill:constant时,设置填充的像素值,RGB or Gray
2. ColorJitter
功能:调整亮度、对比度、饱和度和色相

- brightness:亮度调整因子
- 当为a时,从[max(0, 1-a), 1+a]中随机选择
- 当为(a,b)时,从[a,b]中
- contrast:对比度参数,同brightness
- saturation:饱和度参数,同brightness
- hue:色相参数
- 当为a时,从[-a,a]中选择参数,注:0<=a<=0.5
- 当为(a,b)时,从[a,b]中选择参数,注:-0.5<=a<=b<=0.5
3. Grayscale
4. RandomGrayscale
功能:依概率将图片转换为灰度图
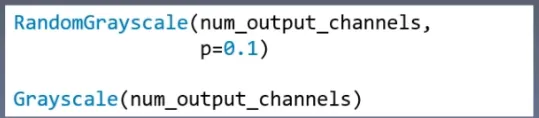
- num_ouput_channels:输出通道数,只能设置1或3
- p:概率值,图像被转换为灰度图的概率
5. RandomAffine
功能:对图像进行仿射变换,仿射变换是二维的线性变换,由五种基本原子变换构成,分别是旋转、平移、缩放、错切和翻转。

- degrees:旋转角度设置
- translate:平移区间设置,如(a,b),a设置宽(width),b设置高(height)
- 图像在宽维度平移的区间为 -img_width *a< dx < img_width *a
- scale:缩放比例(以面积为单位)
- fill_color:填充颜色设置
- shear:错切角度设置,有水平错切和垂直错切
- 若为a,则仅在x轴错切,错切角度在(-a,a)之间
- 若为(a,b),则a设置x轴角度,b设置y的角度
- 若为(a,b,c,d),则a,b设置x轴角度,c,d设置y轴角度
- resample:重采样方式,有NEAREST,BILINEAR,BICUBIC
6. RandomErasing
功能:对图像进行随机遮挡

- p:概率值,执行该操作的概率
- scale:遮挡区域的面积
- ratio:遮挡区域长宽比
- value:设置遮挡区域的像素值,(R,G,B)or(Gray)

7. transforms.Lambda
功能:用户自定义lambda方法

- lambd:lambda匿名函数
- lambda [arg1 [arg2, …, argn]] : expression
在之前我们就用过这个函数:

transforms的操作
1. transforms.RandomChoice
功能:从一系列transforms方法中随机挑选一个

2. transforms.RandomApply
功能:依据概率执行一组transforms操作

3. transforms.RandomOrder
功能:对一组transforms操作打乱顺序

自定义transforms

自定义transforms要素:
- 仅接收一个参数,返回一个参数
- 注意上下游的输出与输入
通过类实现多参数传入:

示例:椒盐噪声
椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑色为椒噪声
信噪比(Signal-Noise Rate,SNR)是衡量噪声的比例,图像中为图像像素的占比
从左到右 信噪比越来越小,椒盐噪声比例越来越大

自定义一个类:

class AddPepperNoise(object):
"""增加椒盐噪声
Args:
snr (float): Signal Noise Rate
p (float): 概率值,依概率执行该操作
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) or (isinstance(p, float))
self.snr = snr
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
if random.uniform(0, 1) < self.p:
img_ = np.array(img).copy()
h, w, c = img_.shape
signal_pct = self.snr
noise_pct = (1 - self.snr)
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # 盐噪声
img_[mask == 2] = 0 # 椒噪声
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img数据增强策略


原则:让训练集与测试集更接近
- 空间位置:平移
- 色彩:灰度图,色彩抖动
- 形状:仿射变换
- 上下文场景:遮挡,填充
- …..
